
introducing silk 1 (beta)
voice for ai companions
published
feb 11, 2026
by
vatsal, pranav, anant, suryansh
"
The voice is a second face." — Gérard Bauer
companionship is still the number one use case for ai, and we’ve been building towards that at rumik.
voice is something that unlocks the companion layer, it gives users freedom in how they express themselves and make every interaction feel closer to human.
we tested many voice models, especially ones equipped with hinglish, tanglish, manglish, and other code-switched patterns, but none were consistent in all the paradigms.
but before we go further, just listen:
if that sounded like someone you'd actually want to talk to, good. that's the whole point!
why we chose to solve voice (first)
in our ultimate quest to solve for human-like ai companions, voice naturally felt like the first modality to solve for, why?
because building ai companions that feel genuinely human requires solving many hard problems. sesame's research : crossing the uncanny valley identifies four essential components:
emotional intelligence: reading and responding to emotional context
conversational dynamics: natural timing, pauses, interruptions
contextual awareness: tone that matches the situation
consistent personality: a coherent, reliable presence
most current voice systems fail in all four. we agree, and we think voice is not just another modality; it's a free axis of expression. text can convey information. voice can convey soul, it conveys emotion, intent, emphasis, humor, hesitation, empathy; all the subtleties text alone can never capture.
the pursuit isn’t novelty; the problems already exist in voice tech: lack of expressive datasets, broken code-switch handling, and shallow evaluations that don’t reflect real human usage.
the data problem (and how we're trying to solve it)
"
In god we trust. All others must bring data." - W. Edwards Deming
also us : cool quote. but where's the data ?
when we started, we had a simple question: where do we get high-quality expressive multi-indic TTS data (including hinglish) with proper code-switching? actually, nowhere.
if we try to paint the real picture:
public datasets for multilingual tts? these are either small, read in formal language, or recorded in conditions that make you question if it was done inside a pressure cooker (literally!)
code-switched data? almost non-existent. and when it exists, transcription is all over the place.
expressive data with emotional tags? [silent background laughter]
transcribing code-switched speech is surprisingly philosophical. take "1926":
did the speaker say "nineteen twenty-six"?
or "unnis sau chabbis" (hindi)?.
or some beautiful hybrid
and more importantly: how should we represent it in text for training?
and because there literally isn’t a blueprint for how to make good expressive data; every step was trial, fire, and careful iteration.
there was no guide on ideal emotion distributions, how much data makes just enough expressivity, what good data even looks like, or how to judge it. real research literature spares almost no attention to these production realities, especially outside english.
here's a partial list of questions we had to figure out ourselves:
what distribution of emotions should training data have?
how many hours of mid-training before expressiveness becomes over-the-top?.
how do you evaluate "good" code-switching at scale?
what's the ideal ratio of mixed-language utterances?
how do you maintain the "desi accent" even when speaking english words?
if an utterance sounds bad, why does it sound bad?
the honest answer to most of these when we started: ¯\_(ツ)_/¯
we ran experiments. we failed. we ran more experiments. and now we are developing internal evaluation frameworks. we're still not sure we have all the answers, but we have better answers than we did.
on the training frenzy
"
a lesson without pain is meaningless. that's because no one can gain anything without sacrificing something." - Edward Elric, Fullmetal Alchemist
we learned a lot of lessons, and here's our sacrifice.
for the base, we began with a transformer backbone based TTS model that treats speech generation like next-token prediction. the architecture made sense: train a language model to output discrete audio codes, then decode them back to waveforms (using a latent encoder-decoder).
pre-existing multilingual tts models existed, trained on multilingual corpora which should ideally be the perfect starting point right? actually no. our first experiments were... humbling. the outputs were filled with artifacts and noise. not subtle issues, genuinely bad audio.
we dug into why.
looking at training data mix from open source reports, the pattern became clear: most base models are primarily english, with continued pretraining on multilingual corpora. but here's the thing about how people actually text and communicate:
it wasn’t just hindi + english. we saw the same fracture across tamil + english (tanglish), malayalam + english (manglish), kannada + english, bengali + english, you name it. and not in clean native scripts either. often in latin script. often phonetically inconsistent. often within the same sentence.
not this: मैं कल मिलूंगा (hindi) or நான் நாளைக்கு வருவேன் (tamil)
but this: main kal milunga (hinglish) or naan naalaikku varuven (tanglish)
the model had learned english acoustics. and other sounds separately. it had learned tamil, malayalam, hindi, and others too but it learned them like separate islands.
what it hadn't learned was how they blend the smooth transitions, the preserved accent, the natural prosody when switching mid-sentence. our job became less about adding languages, and more about teaching the model how languages coexist inside the same human breath.
the emotion gap. while the base system supported emotions, the mulitilingual version didn't. for our use case: expressive, companion-like speech, this was a dealbreaker and hence we introduced mid-sentence emotional tags along with light descriptions of tone and prosody into training:
<laugh> arey yaar, <excited> you won't believe what happened!
<warm tone with light jolt> main toh literally shock mein tha.
this format lets us control emotions dynamically within utterances, not just set-and-forget at the start.
we started simple. the model was clear, but it sounded flat, like it was just reading words off a page. we ran a lot of controlled experiments to figure out what was actually helping and what wasn’t. some changes improved things, but the results were inconsistent. the real progress came when we fixed the training dynamics so the model could adapt more gradually instead of being forced into a new distribution overnight.
and once we moved from a single speaker to a diverse set of voices, the model stopped copying surface quirks and started learning how speech actually works. that’s when quality and generalization noticeably improved.
evals are hard
there is no benchmark. evaluating voice models is… messy. for LLMs, we have, MMLU, HumanEval, HellaSwag. etc. for TTS, the landscape is thinner.
MOS (mean opinion score) is subjective and expensive. WER (word error rate) measures intelligibility, not quality. preference tests (like speech arena) help, but they’re mostly english-focused. when you care about code-switching, accent retention, or emotional nuance in mulitilingual contexts, there isn’t a clean number to point to.
the vibe eval problem. right now, evaluating expressive TTS is still largely manual: we generate samples, listen as a group, debate whether it sounds natural, and make a call. sometimes even do blind tests. there’s no scalable “voice-as-judge” equivalent to LLM-as-judge that can reliably score emotional authenticity or code-switching fluency. so a significant part of evaluation still depends on human perception.
we think the path forward runs through interpretability. by understanding how these models internally encode emotional nuance and linguistic context, we can develop evaluation frameworks that are both scalable and grounded, metrics that capture not just whether a sample sounds right, but what the model is actually doing to produce it.
on interpretability of TTS models
here's where we get excited, and specifically no lab is trying to solve for these challenges. we believe that understanding what a TTS model has learned, really understanding it, is an underexplored frontier.
here are some teasers (from our probe experiments):
we trained a linear probe on residual stream vectors to predict a binary ENG/HIN label per token. the probe is a logistic regression classifier, so success implies the language signal is linearly encoded at that layer.
single-switch sentence : "i was going home jab baarish shuru hui."
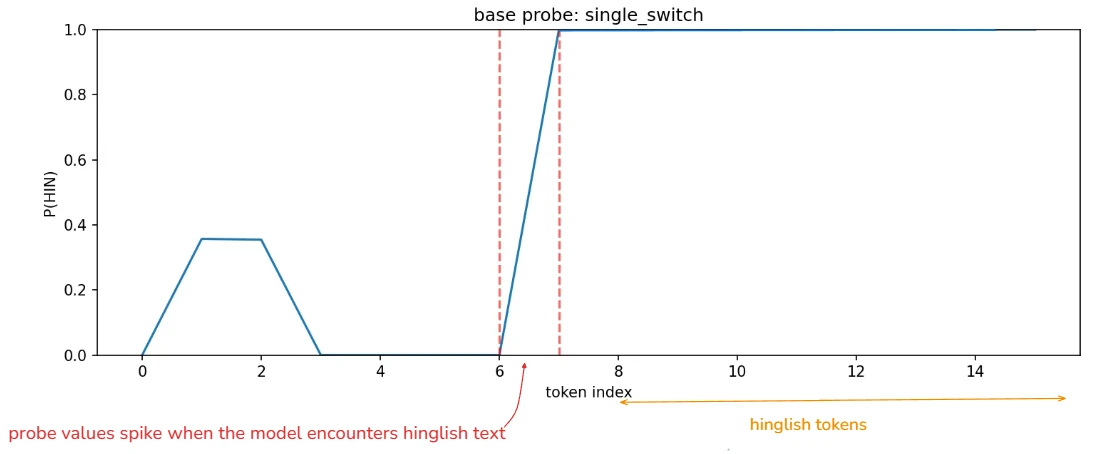
in the above plot, the probe probability rises sharply when the model encounters hindi tokens, and drops when english resumes. this indicates a strong lexical hindi signal in the residual stream rather than a persistent language‑mode state.
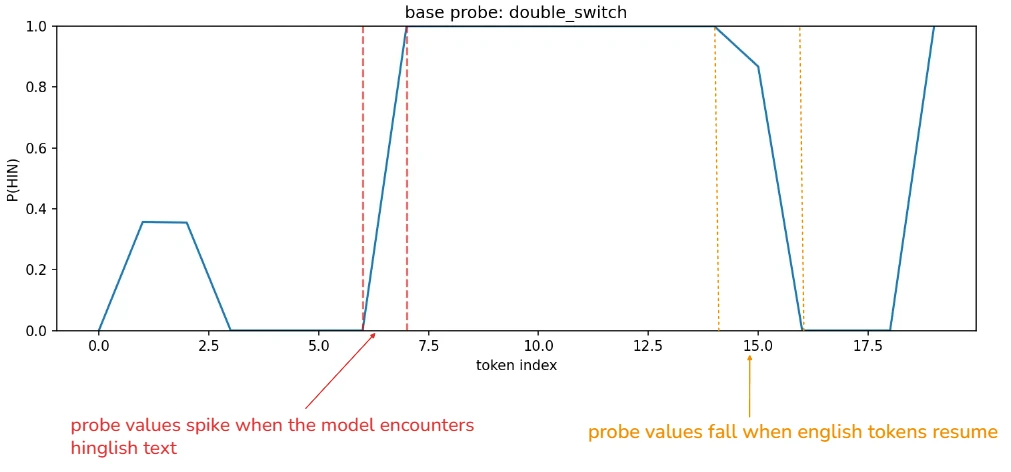
double-switch sentence : "i was going home jab baarish shuru hui and i got wet."
in the double‑switch sentence, the probe again jumps to high P(HIN) at the hindi boundary, but then falls back toward zero once the english continuation resumes.
this rise‑and‑fall pattern mirrors the lexical content: the classifier responds strongly to hindi tokens, but the signal decays when the sequence returns to english.
the behavior is consistent across base and hinglish models, suggesting that the probe is reading lexical hindi features rather than tracking a persistent language‑mode state across the second english segment.
let's look at a few voice designs.
what to expect from us. we’re continuing to invest in interpretability; more transparency into training behavior, emotional control, and code-switching dynamics is coming soon!
we’re also preparing to release silk 1 - mulberry (our open source model from silk series), with improvements across stability, expressiveness, and multilingual blending.
get early access
want to try silk 1 beta? we're opening early access to a limited group of folks building voice experiences for ai companions.
silk 1 is already powering voice inside ira (our ai companion product), where users spend over 100k minutes a day talking to it. we’ve brought latency down to ~300ms on average, fast enough for conversations to feel real.
we're a small team that believes voice ai in india deserves better. this is our first public research(preview), but not our last.
if you're working on similar problems and want to collaborate, we'd love to hear from you.