

silk mulberry 1.5 is the fastest, most cost-effective model in the silk family. it's designed for real-time voice applications, and its most important feature is the power of voice design.

what makes mulberry special
most text-to-speech systems give you a dropdown. pick voice a, b, or c: all of them flat, all of them someone else's idea of what "natural" sounds like. you've heard them everywhere: customer support bots, audiobook narrators, accessibility readers. after a while, they all start to blur together.
that monotony was the starting point for silk mulberry.
we wanted to build a text-to-speech system where, instead of picking from a preset list, you could describe the voice you want in plain language, and get it. not a close approximation. not a best-effort match. a voice that reflects the specific combination of traits you asked for: the speaker's age, gender presentation, emotional register, timbre, pitch, accent, and even how they switch between languages mid-sentence.
soo what makes mulberry different? at its core, mulberry is an audio language model. that distinction matters more than it might seem.
the basic pipeline is: a base LLM generates speech tokens from your text, conditioned on your voice description. those tokens then get decoded by an audio decoder into a final waveform. because everything is token-based, generation can happen in a streaming fashion, frame-by-frame (token accumulate to form a frame), rather than waiting for the full audio to render.
during inference the pipeline looks like:
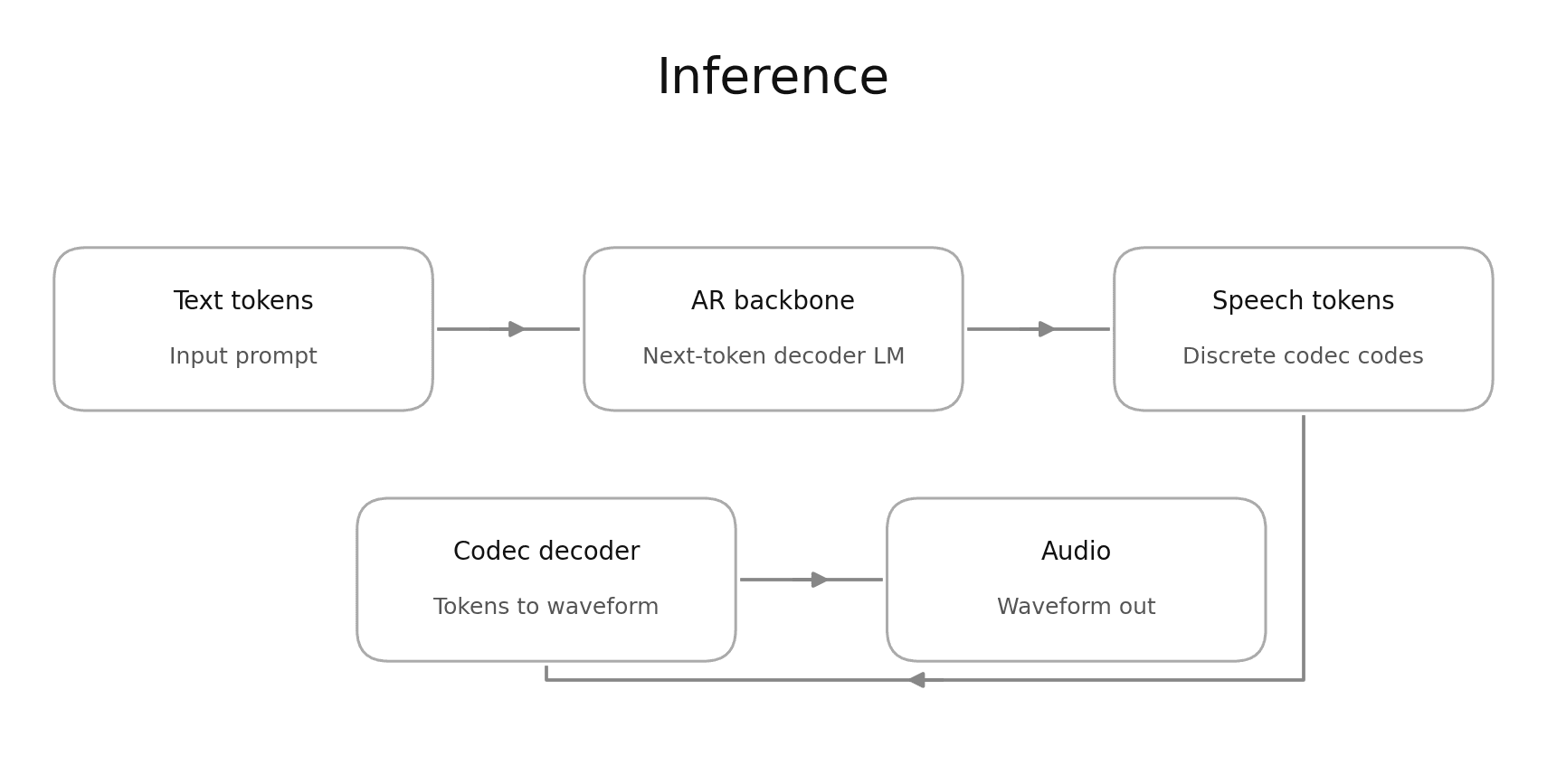
during training, the encoder is involved for discretizing audio waveforms to to speech tokens. we can now make the transformer backbone learn to predict those speech tokens using standard cross entropy loss. this helps keep the design simple and robust.

why a transformer backbone ?
the language-model backbone buys us three things that are genuinely hard to get otherwise.
streaming with low latency.
token-by-token generation means the first chunk of audio can arrive fast. on a single h100 gpu, we're seeing under 200ms time-to-first-chunk, even at 80 concurrent requests.
better handling of ambiguous text.
the same word can be pronounced differently depending on context, think "read" (present vs. past tense), or technical abbreviations that get expanded differently in different domains. an llm backbone can resolve those ambiguities using surrounding context, the way a human reader would.
generalization across phrasing.
this one is subtle but important. if we train the model on "indian man speaking in haryaanvi accent, in his 30s," we want it to also respond correctly to "haryanvi mid-aged man." because the model builds contextual representations via attention rather than relying on exact string matches, it can often bridge those semantic gaps without additional training data. description variants that mean the same thing tend to land in the same place.
voice designs that mulberry brings to the table
getting voice designs right required some careful thinking about how to structure the training data.
because we were working within a constrained parameter budget, we made a deliberate call: discretize the voice design space. rather than asking the model to handle an open-ended range of descriptions, we curated a specific set of traits, accents, and characteristics, then trained the model to map closely related phrasings onto the same target behavior.
in practice, that means if the model was trained on "indian male voice, hinglish accent, with low pitch," it can still interpret "man in his 20s speaking hinglish accent with deep voice" correctly at inference time. the surface-level wording changes; the underlying voice design doesn't.
some examples :
description: a) female speaking in haryaanvi accent
description: b) a female voice in her 30s with a haryanvi accent and a conversational pace.
description: a) deep voice male
description: b) man speaking low pitched voice.
description: a) female speaking in robotic voice.
description: b) female monotonous voice
here, the descriptions on the right side are the actual descriptions on which the model was trained on, and the left side are the ones which the model can also pickup at inference time.
voice design generates speakers on the fly, when speaker tags are not specified in the model, then speaker is decided using combination of gender, pitch, age.
to reason about training behavior while adopting such designs we also did mechanistic interpretability research focused specifically on code-switching , the model's ability to move cleanly between languages (like english and hindi) while keeping the voice identity stable. that research helped us identify and strengthen the internal circuits responsible for that behavior.
mech interp insights from mulberry
here are some of the probe experiments we did and what we found:
we trained a linear probe on residual stream vectors to predict a binary ENG/HIN label per token. the probe is a classifier, so success implies the language signal is linearly encoded at that layer.
single-switch sentence : "i was going home jab baarish shuru hui."

in the above plot, the probe probability rises sharply when the model encounters hindi tokens, and drops when english resumes. this indicates a strong lexical hindi signal in the residual stream rather than a persistent language‑mode state..
double-switch sentence : "i was going home jab baarish shuru hui and i got wet."
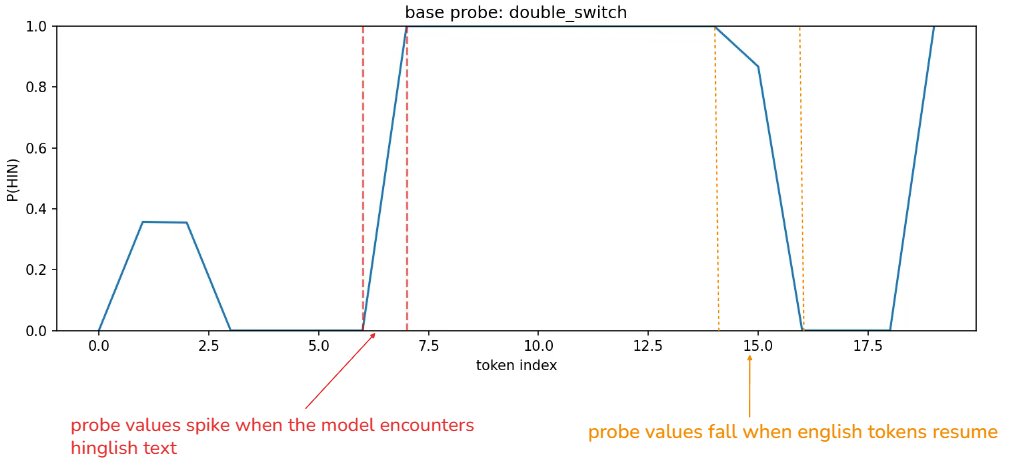
in the double‑switch sentence, the probe again jumps to high P(HIN) at the hindi boundary, but then falls back toward zero once the english continuation resumes.
this rise‑and‑fall pattern mirrors the lexical content: the classifier responds strongly to hindi tokens, but the signal decays when the sequence returns to english.
the behavior is consistent across base and hinglish models, suggesting that the probe is reading lexical hindi features rather than tracking a persistent language‑mode state across the second english segment.
stay tuned to know about this in detail!
benchmarks

for serving, mulberry builds on inference optimizations originally developed for llms. we adapt engines such as tensorrt-llm to our decoder architecture, allowing us to reuse mature serving infrastructure while supporting mulberry’s specific model design
on a single h100:
~80 concurrent real-time requests
<200ms time-to-first-audio
<0.9 real-time factor at 80-way concurrency
~162ms TTFB at ~5 concurrent requests
here, TTFB is the time from sending the request to receiving the first byte of the response, while TTFA is the time from sending the request to the first chunk of synthesized audio, after skipping past any container or header metadata.
mechanism
input: a short standardized text prompt of around 15-25 words, used consistently across all providers tested.
output: output format and sample rate kept fixed for all test runs.
geographic region: measured from a US-based client location, where we recorded a TTFA of 179ms.
mos scores

for quality, we use xls-r sqa mos as our primary metric. mulberry scores 4.23 ± 0.14, which puts it close to elevenlabs v3 (4.26) and gemini 3.1 flash tts (4.3). we're not claiming to beat the field, but we're competitive, and the voice control capabilities are meaningfully different.
instructTTS eval

since our model follows description style instruction following for speaker and other prosody features, we also evaluated our model on InstructTTS Eval, which is a benchmark designed to evaluate how well TTS systems follow complex natural-language instructions for controlling paralinguistic features (like pitch, emotion and prosody).
the benchmark consists of 6,000 test cases divided into three hierarichal tasks that progress from concrete control to abstract reasoning.
Acoustic-Parameter Specification (APS): Models are given explicit instructions for 12 fine-grained features (e.g., pitch, speed, volume, emotion).
Descriptive-Style Directive (DSD): Models receive more natural, free-form qualitative descriptions of a voice style.
Role-Play (RP): Models must infer appropriate vocal styles from abstract scenarios or character descriptions (e.g., "a teacher scolding a student").
for evaluating the audio generated for a given description, we used gemini 2.5 pro as judge (as used by authors) to give binary results (i.e. either pass or fail). the final score reported for each TTS system is the accuracy percentage, calculated as the macro-average of “True” judgements across all 1,000 test cases in a given subset.
on the instructTTS eval benchmark, mulberry hits 74.13% overall consistency. with scores of 75.30% on APS, 82.70% on DSD, and 64.40% on RP.
insights from pre-training
warm-start vs cold-start pre-training

when comparing the cold-start approach (scratch pre-training on text-audio pairs) against the warm-start approach (starting directly from a text base), the cold-start variant surprisingly comes out on top. as shown in the loss curves for both mulberry-small and mulberry-large, the cold-start runs yield a significantly smoother, more stable improvement over time. conversely, the warm-start configurations introduce frequent training instability, with small-warm-start even experiencing a massive loss spike midway through.
this distinct performance gap suggests that pre-trained text weights might actually conflict with or interfere with the model's ability to cleanly map acoustic inputs to text representations, a phenomenon noted and analyzed in the literature.
data prep and formatting
for data preparation, we used a blend of synthetic and proprietary real-world audio, applying standard pre-processing steps like speaker diarization, background noise removal, and vad trimming. to prevent redundancy, we handled text de-duplication and canonicalization, then scaled our variations by pairing identical text with diverse audio descriptions and rvc-converted voices. rather than replacing features, we expanded the model's capabilities by introducing each new speaker category through dedicated description buckets. after initial pre-training on an internet-scale english speech corpus to lock in broad acoustics and coarticulation, we moved to sft using a curated mix of synthetic and studio voices that covered a wide array of regional accents, characters, and role variations.

our data formatting relies on a straightforward yet highly effective token recipe: interleaving text and audio pairs. as illustrated in the image above, this can be structured either as utterance-level interleaving or a more granular semantic and acoustic interleaving. by adopting this interleaved style for our tokens, the model easily learns the associative layout between audio-to-text or text-to-audio sequences without needing over-engineered training formats.
and what's next
if you're building with mulberry, the most important thing to keep in mind is that voice descriptions work best when they're grounded in the trait categories the model was trained on. the prompting guide walks through the supported attributes in detail, keeping your descriptions structured and consistent will get you the most predictable results.
that said, the generalization behavior means you have real flexibility in how you phrase things, even if the underlying traits are fixed. we're continuing to expand the set of supported accents, speaking styles, and code-switching behaviors, so if there are voice descriptions you want to see supported, that's the right place to start the conversation.
so take mulberry for a spin on the rumik playground now!
many researchers assume that if they use muP (a method by Yang et al, 2022, for transferring hyperparameters across model sizes), they are safe from LR-tuning headaches.
what makes mulberry special
most text-to-speech systems give you a dropdown. pick voice a, b, or c: all of them flat, all of them someone else's idea of what "natural" sounds like. you've heard them everywhere: customer support bots, audiobook narrators, accessibility readers. after a while, they all start to blur together.
that monotony was the starting point for silk mulberry.
we wanted to build a text-to-speech system where, instead of picking from a preset list, you could describe the voice you want in plain language, and get it. not a close approximation. not a best-effort match. a voice that reflects the specific combination of traits you asked for: the speaker's age, gender presentation, emotional register, timbre, pitch, accent, and even how they switch between languages mid-sentence.
soo what makes mulberry different? at its core, mulberry is an audio language model. that distinction matters more than it might seem.
the basic pipeline is: a base LLM generates speech tokens from your text, conditioned on your voice description. those tokens then get decoded by an audio decoder into a final waveform. because everything is token-based, generation can happen in a streaming fashion, frame-by-frame (token accumulate to form a frame), rather than waiting for the full audio to render.
during inference the pipeline looks like:
during training, the encoder is involved for discretizing audio waveforms to to speech tokens. we can now make the transformer backbone learn to predict those speech tokens using standard cross entropy loss. this helps keep the design simple and robust.
why a transformer backbone ?
the language-model backbone buys us three things that are genuinely hard to get otherwise.
streaming with low latency.
token-by-token generation means the first chunk of audio can arrive fast. on a single h100 gpu, we're seeing under 200ms time-to-first-chunk, even at 80 concurrent requests.
better handling of ambiguous text.
the same word can be pronounced differently depending on context, think "read" (present vs. past tense), or technical abbreviations that get expanded differently in different domains. an llm backbone can resolve those ambiguities using surrounding context, the way a human reader would.
generalization across phrasing.
this one is subtle but important. if we train the model on "indian man speaking in haryaanvi accent, in his 30s," we want it to also respond correctly to "haryanvi mid-aged man." because the model builds contextual representations via attention rather than relying on exact string matches, it can often bridge those semantic gaps without additional training data. description variants that mean the same thing tend to land in the same place.
voice designs that mulberry brings to the table
getting voice designs right required some careful thinking about how to structure the training data.
because we were working within a constrained parameter budget, we made a deliberate call: discretize the voice design space. rather than asking the model to handle an open-ended range of descriptions, we curated a specific set of traits, accents, and characteristics, then trained the model to map closely related phrasings onto the same target behavior.
in practice, that means if the model was trained on "indian male voice, hinglish accent, with low pitch," it can still interpret "man in his 20s speaking hinglish accent with deep voice" correctly at inference time. the surface-level wording changes; the underlying voice design doesn't.
some examples :
description: a) female speaking in haryaanvi accent
description: b) a female voice in her 30s with a haryanvi accent and a conversational pace.
description: a) deep voice male
description: b) man speaking low pitched voice.
description: a) female speaking in robotic voice.
description: b) female monotonous voice
here, the descriptions on the right side are the actual descriptions on which the model was trained on, and the left side are the ones which the model can also pickup at inference time.
voice design generates speakers on the fly, when speaker tags are not specified in the model, then speaker is decided using combination of gender, pitch, age.
to reason about training behavior while adopting such designs we also did mechanistic interpretability research focused specifically on code-switching , the model's ability to move cleanly between languages (like english and hindi) while keeping the voice identity stable. that research helped us identify and strengthen the internal circuits responsible for that behavior.
mech interp insights from mulberry
here are some of the probe experiments we did and what we found:
we trained a linear probe on residual stream vectors to predict a binary ENG/HIN label per token. the probe is a classifier, so success implies the language signal is linearly encoded at that layer.
single-switch sentence : "i was going home jab baarish shuru hui."
in the above plot, the probe probability rises sharply when the model encounters hindi tokens, and drops when english resumes. this indicates a strong lexical hindi signal in the residual stream rather than a persistent language‑mode state..
double-switch sentence : "i was going home jab baarish shuru hui and i got wet."
in the double‑switch sentence, the probe again jumps to high P(HIN) at the hindi boundary, but then falls back toward zero once the english continuation resumes.
this rise‑and‑fall pattern mirrors the lexical content: the classifier responds strongly to hindi tokens, but the signal decays when the sequence returns to english.
the behavior is consistent across base and hinglish models, suggesting that the probe is reading lexical hindi features rather than tracking a persistent language‑mode state across the second english segment.
stay tuned to know about this in detail!
benchmarks
for serving, mulberry builds on inference optimizations originally developed for llms. we adapt engines such as tensorrt-llm to our decoder architecture, allowing us to reuse mature serving infrastructure while supporting mulberry’s specific model design
on a single h100:
~80 concurrent real-time requests
<200ms time-to-first-audio
<0.9 real-time factor at 80-way concurrency
~162ms TTFB at ~5 concurrent requests
here, TTFB is the time from sending the request to receiving the first byte of the response, while TTFA is the time from sending the request to the first chunk of synthesized audio, after skipping past any container or header metadata.
mechanism
input: a short standardized text prompt of around 15-25 words, used consistently across all providers tested.
output: output format and sample rate kept fixed for all test runs.
geographic region: measured from a US-based client location, where we recorded a TTFA of 179ms.
mos scores
for quality, we use xls-r sqa mos as our primary metric. mulberry scores 4.23 ± 0.14, which puts it close to elevenlabs v3 (4.26) and gemini 3.1 flash tts (4.3). we're not claiming to beat the field, but we're competitive, and the voice control capabilities are meaningfully different.
instructTTS eval
since our model follows description style instruction following for speaker and other prosody features, we also evaluated our model on InstructTTS Eval, which is a benchmark designed to evaluate how well TTS systems follow complex natural-language instructions for controlling paralinguistic features (like pitch, emotion and prosody).
the benchmark consists of 6,000 test cases divided into three hierarichal tasks that progress from concrete control to abstract reasoning.
Acoustic-Parameter Specification (APS): Models are given explicit instructions for 12 fine-grained features (e.g., pitch, speed, volume, emotion).
Descriptive-Style Directive (DSD): Models receive more natural, free-form qualitative descriptions of a voice style.
Role-Play (RP): Models must infer appropriate vocal styles from abstract scenarios or character descriptions (e.g., "a teacher scolding a student").
for evaluating the audio generated for a given description, we used gemini 2.5 pro as judge (as used by authors) to give binary results (i.e. either pass or fail). the final score reported for each TTS system is the accuracy percentage, calculated as the macro-average of “True” judgements across all 1,000 test cases in a given subset.
on the instructTTS eval benchmark, mulberry hits 74.13% overall consistency. with scores of 75.30% on APS, 82.70% on DSD, and 64.40% on RP.
insights from pre-training
warm-start vs cold-start pre-training
when comparing the cold-start approach (scratch pre-training on text-audio pairs) against the warm-start approach (starting directly from a text base), the cold-start variant surprisingly comes out on top. as shown in the loss curves for both mulberry-small and mulberry-large, the cold-start runs yield a significantly smoother, more stable improvement over time. conversely, the warm-start configurations introduce frequent training instability, with small-warm-start even experiencing a massive loss spike midway through.
this distinct performance gap suggests that pre-trained text weights might actually conflict with or interfere with the model's ability to cleanly map acoustic inputs to text representations, a phenomenon noted and analyzed in the literature.
data prep and formatting
for data preparation, we used a blend of synthetic and proprietary real-world audio, applying standard pre-processing steps like speaker diarization, background noise removal, and vad trimming. to prevent redundancy, we handled text de-duplication and canonicalization, then scaled our variations by pairing identical text with diverse audio descriptions and rvc-converted voices. rather than replacing features, we expanded the model's capabilities by introducing each new speaker category through dedicated description buckets. after initial pre-training on an internet-scale english speech corpus to lock in broad acoustics and coarticulation, we moved to sft using a curated mix of synthetic and studio voices that covered a wide array of regional accents, characters, and role variations.
our data formatting relies on a straightforward yet highly effective token recipe: interleaving text and audio pairs. as illustrated in the image above, this can be structured either as utterance-level interleaving or a more granular semantic and acoustic interleaving. by adopting this interleaved style for our tokens, the model easily learns the associative layout between audio-to-text or text-to-audio sequences without needing over-engineered training formats.
and what's next
if you're building with mulberry, the most important thing to keep in mind is that voice descriptions work best when they're grounded in the trait categories the model was trained on. the prompting guide walks through the supported attributes in detail, keeping your descriptions structured and consistent will get you the most predictable results.
that said, the generalization behavior means you have real flexibility in how you phrase things, even if the underlying traits are fixed. we're continuing to expand the set of supported accents, speaking styles, and code-switching behaviors, so if there are voice descriptions you want to see supported, that's the right place to start the conversation.
so take mulberry for a spin on the rumik playground now!
silk mulberry 1.5 is the fastest, most cost-effective model in the silk family. it's designed for real-time voice applications, and its most important feature is the power of voice design.
what makes mulberry special
most text-to-speech systems give you a dropdown. pick voice a, b, or c: all of them flat, all of them someone else's idea of what "natural" sounds like. you've heard them everywhere: customer support bots, audiobook narrators, accessibility readers. after a while, they all start to blur together.
that monotony was the starting point for silk mulberry.
we wanted to build a text-to-speech system where, instead of picking from a preset list, you could describe the voice you want in plain language, and get it. not a close approximation. not a best-effort match. a voice that reflects the specific combination of traits you asked for: the speaker's age, gender presentation, emotional register, timbre, pitch, accent, and even how they switch between languages mid-sentence.
soo what makes mulberry different? at its core, mulberry is an audio language model. that distinction matters more than it might seem.
the basic pipeline is: a base LLM generates speech tokens from your text, conditioned on your voice description. those tokens then get decoded by an audio decoder into a final waveform. because everything is token-based, generation can happen in a streaming fashion, frame-by-frame (token accumulate to form a frame), rather than waiting for the full audio to render.
during inference the pipeline looks like:
during training, the encoder is involved for discretizing audio waveforms to to speech tokens. we can now make the transformer backbone learn to predict those speech tokens using standard cross entropy loss. this helps keep the design simple and robust.
why a transformer backbone ?
the language-model backbone buys us three things that are genuinely hard to get otherwise.
streaming with low latency.
token-by-token generation means the first chunk of audio can arrive fast. on a single h100 gpu, we're seeing under 200ms time-to-first-chunk, even at 80 concurrent requests.
better handling of ambiguous text.
the same word can be pronounced differently depending on context, think "read" (present vs. past tense), or technical abbreviations that get expanded differently in different domains. an llm backbone can resolve those ambiguities using surrounding context, the way a human reader would.
generalization across phrasing.
this one is subtle but important. if we train the model on "indian man speaking in haryaanvi accent, in his 30s," we want it to also respond correctly to "haryanvi mid-aged man." because the model builds contextual representations via attention rather than relying on exact string matches, it can often bridge those semantic gaps without additional training data. description variants that mean the same thing tend to land in the same place.
voice designs that mulberry brings to the table
getting voice designs right required some careful thinking about how to structure the training data.
because we were working within a constrained parameter budget, we made a deliberate call: discretize the voice design space. rather than asking the model to handle an open-ended range of descriptions, we curated a specific set of traits, accents, and characteristics, then trained the model to map closely related phrasings onto the same target behavior.
in practice, that means if the model was trained on "indian male voice, hinglish accent, with low pitch," it can still interpret "man in his 20s speaking hinglish accent with deep voice" correctly at inference time. the surface-level wording changes; the underlying voice design doesn't.
some examples :
description: a) female speaking in haryaanvi accent
description: b) a female voice in her 30s with a haryanvi accent and a conversational pace.
description: a) deep voice male
description: b) man speaking low pitched voice.
description: a) female speaking in robotic voice.
description: b) female monotonous voice
here, the descriptions on the right side are the actual descriptions on which the model was trained on, and the left side are the ones which the model can also pickup at inference time.
voice design generates speakers on the fly, when speaker tags are not specified in the model, then speaker is decided using combination of gender, pitch, age.
to reason about training behavior while adopting such designs we also did mechanistic interpretability research focused specifically on code-switching , the model's ability to move cleanly between languages (like english and hindi) while keeping the voice identity stable. that research helped us identify and strengthen the internal circuits responsible for that behavior.
mech interp insights from mulberry
here are some of the probe experiments we did and what we found:
we trained a linear probe on residual stream vectors to predict a binary ENG/HIN label per token. the probe is a classifier, so success implies the language signal is linearly encoded at that layer.
single-switch sentence : "i was going home jab baarish shuru hui."
in the above plot, the probe probability rises sharply when the model encounters hindi tokens, and drops when english resumes. this indicates a strong lexical hindi signal in the residual stream rather than a persistent language‑mode state..
double-switch sentence : "i was going home jab baarish shuru hui and i got wet."
in the double‑switch sentence, the probe again jumps to high P(HIN) at the hindi boundary, but then falls back toward zero once the english continuation resumes.
this rise‑and‑fall pattern mirrors the lexical content: the classifier responds strongly to hindi tokens, but the signal decays when the sequence returns to english.
the behavior is consistent across base and hinglish models, suggesting that the probe is reading lexical hindi features rather than tracking a persistent language‑mode state across the second english segment.
stay tuned to know about this in detail!
benchmarks
for serving, mulberry builds on inference optimizations originally developed for llms. we adapt engines such as tensorrt-llm to our decoder architecture, allowing us to reuse mature serving infrastructure while supporting mulberry’s specific model design
on a single h100:
~80 concurrent real-time requests
<200ms time-to-first-audio
<0.9 real-time factor at 80-way concurrency
~162ms TTFB at ~5 concurrent requests
here, TTFB is the time from sending the request to receiving the first byte of the response, while TTFA is the time from sending the request to the first chunk of synthesized audio, after skipping past any container or header metadata.
mechanism
input: a short standardized text prompt of around 15-25 words, used consistently across all providers tested.
output: output format and sample rate kept fixed for all test runs.
geographic region: measured from a US-based client location, where we recorded a TTFA of 179ms.
mos scores
for quality, we use xls-r sqa mos as our primary metric. mulberry scores 4.23 ± 0.14, which puts it close to elevenlabs v3 (4.26) and gemini 3.1 flash tts (4.3). we're not claiming to beat the field, but we're competitive, and the voice control capabilities are meaningfully different.
instructTTS eval
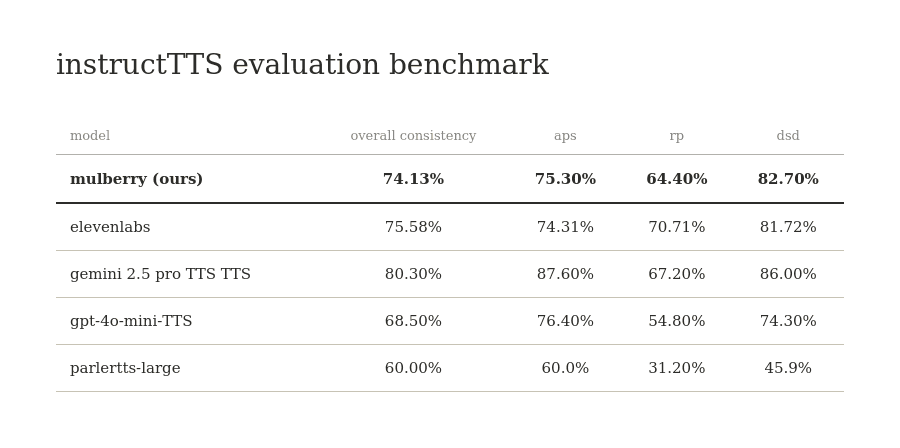
since our model follows description style instruction following for speaker and other prosody features, we also evaluated our model on InstructTTS Eval, which is a benchmark designed to evaluate how well TTS systems follow complex natural-language instructions for controlling paralinguistic features (like pitch, emotion and prosody).
the benchmark consists of 6,000 test cases divided into three hierarichal tasks that progress from concrete control to abstract reasoning.
Acoustic-Parameter Specification (APS): Models are given explicit instructions for 12 fine-grained features (e.g., pitch, speed, volume, emotion).
Descriptive-Style Directive (DSD): Models receive more natural, free-form qualitative descriptions of a voice style.
Role-Play (RP): Models must infer appropriate vocal styles from abstract scenarios or character descriptions (e.g., "a teacher scolding a student").
for evaluating the audio generated for a given description, we used gemini 2.5 pro as judge (as used by authors) to give binary results (i.e. either pass or fail). the final score reported for each TTS system is the accuracy percentage, calculated as the macro-average of “True” judgements across all 1,000 test cases in a given subset.
on the instructTTS eval benchmark, mulberry hits 74.13% overall consistency. with scores of 75.30% on APS, 82.70% on DSD, and 64.40% on RP.
insights from pre-training
warm-start vs cold-start pre-training
when comparing the cold-start approach (scratch pre-training on text-audio pairs) against the warm-start approach (starting directly from a text base), the cold-start variant surprisingly comes out on top. as shown in the loss curves for both mulberry-small and mulberry-large, the cold-start runs yield a significantly smoother, more stable improvement over time. conversely, the warm-start configurations introduce frequent training instability, with small-warm-start even experiencing a massive loss spike midway through.
this distinct performance gap suggests that pre-trained text weights might actually conflict with or interfere with the model's ability to cleanly map acoustic inputs to text representations, a phenomenon noted and analyzed in the literature.
most of the plots and ideas (especially the equations) were taken from this paper and if you've made it till here, i definitely recommend you to give it a read.
data prep and formatting
for data preparation, we used a blend of synthetic and proprietary real-world audio, applying standard pre-processing steps like speaker diarization, background noise removal, and vad trimming. to prevent redundancy, we handled text de-duplication and canonicalization, then scaled our variations by pairing identical text with diverse audio descriptions and rvc-converted voices. rather than replacing features, we expanded the model's capabilities by introducing each new speaker category through dedicated description buckets. after initial pre-training on an internet-scale english speech corpus to lock in broad acoustics and coarticulation, we moved to sft using a curated mix of synthetic and studio voices that covered a wide array of regional accents, characters, and role variations.
our data formatting relies on a straightforward yet highly effective token recipe: interleaving text and audio pairs. as illustrated in the image above, this can be structured either as utterance-level interleaving or a more granular semantic and acoustic interleaving. by adopting this interleaved style for our tokens, the model easily learns the associative layout between audio-to-text or text-to-audio sequences without needing over-engineered training formats.
and what's next
if you're building with mulberry, the most important thing to keep in mind is that voice descriptions work best when they're grounded in the trait categories the model was trained on. the prompting guide walks through the supported attributes in detail, keeping your descriptions structured and consistent will get you the most predictable results.
that said, the generalization behavior means you have real flexibility in how you phrase things, even if the underlying traits are fixed. we're continuing to expand the set of supported accents, speaking styles, and code-switching behaviors, so if there are voice descriptions you want to see supported, that's the right place to start the conversation.
so take mulberry for a spin on the rumik playground now!
silk mulberry 1.5 is the fastest, most cost-effective model in the silk family. it's designed for real-time voice applications, and its most important feature is the power of voice design.
what makes mulberry special
most text-to-speech systems give you a dropdown. pick voice a, b, or c: all of them flat, all of them someone else's idea of what "natural" sounds like. you've heard them everywhere: customer support bots, audiobook narrators, accessibility readers. after a while, they all start to blur together.
that monotony was the starting point for silk mulberry.
we wanted to build a text-to-speech system where, instead of picking from a preset list, you could describe the voice you want in plain language, and get it. not a close approximation. not a best-effort match. a voice that reflects the specific combination of traits you asked for: the speaker's age, gender presentation, emotional register, timbre, pitch, accent, and even how they switch between languages mid-sentence.
soo what makes mulberry different? at its core, mulberry is an audio language model. that distinction matters more than it might seem.
the basic pipeline is: a base LLM generates speech tokens from your text, conditioned on your voice description. those tokens then get decoded by an audio decoder into a final waveform. because everything is token-based, generation can happen in a streaming fashion, frame-by-frame (token accumulate to form a frame), rather than waiting for the full audio to render.
during inference the pipeline looks like:
during training, the encoder is involved for discretizing audio waveforms to to speech tokens. we can now make the transformer backbone learn to predict those speech tokens using standard cross entropy loss. this helps keep the design simple and robust.
why a transformer backbone ?
the language-model backbone buys us three things that are genuinely hard to get otherwise.
streaming with low latency.
token-by-token generation means the first chunk of audio can arrive fast. on a single h100 gpu, we're seeing under 200ms time-to-first-chunk, even at 80 concurrent requests.
better handling of ambiguous text.
the same word can be pronounced differently depending on context, think "read" (present vs. past tense), or technical abbreviations that get expanded differently in different domains. an llm backbone can resolve those ambiguities using surrounding context, the way a human reader would.
generalization across phrasing.
this one is subtle but important. if we train the model on "indian man speaking in haryaanvi accent, in his 30s," we want it to also respond correctly to "haryanvi mid-aged man." because the model builds contextual representations via attention rather than relying on exact string matches, it can often bridge those semantic gaps without additional training data. description variants that mean the same thing tend to land in the same place.
voice designs that mulberry brings to the table
getting voice designs right required some careful thinking about how to structure the training data.
because we were working within a constrained parameter budget, we made a deliberate call: discretize the voice design space. rather than asking the model to handle an open-ended range of descriptions, we curated a specific set of traits, accents, and characteristics, then trained the model to map closely related phrasings onto the same target behavior.
in practice, that means if the model was trained on "indian male voice, hinglish accent, with low pitch," it can still interpret "man in his 20s speaking hinglish accent with deep voice" correctly at inference time. the surface-level wording changes; the underlying voice design doesn't.
some examples :
description: a) female speaking in haryaanvi accent
description: b) a female voice in her 30s with a haryanvi accent and a conversational pace.
description: a) deep voice male
description: b) man speaking low pitched voice.
description: a) female speaking in robotic voice.
description: b) female monotonous voice
here, the descriptions on the right side are the actual descriptions on which the model was trained on, and the left side are the ones which the model can also pickup at inference time.
voice design generates speakers on the fly, when speaker tags are not specified in the model, then speaker is decided using combination of gender, pitch, age.
to reason about training behavior while adopting such designs we also did mechanistic interpretability research focused specifically on code-switching , the model's ability to move cleanly between languages (like english and hindi) while keeping the voice identity stable. that research helped us identify and strengthen the internal circuits responsible for that behavior.
mech interp insights from mulberry
here are some of the probe experiments we did and what we found:
we trained a linear probe on residual stream vectors to predict a binary ENG/HIN label per token. the probe is a classifier, so success implies the language signal is linearly encoded at that layer.
single-switch sentence : "i was going home jab baarish shuru hui."
in the above plot, the probe probability rises sharply when the model encounters hindi tokens, and drops when english resumes. this indicates a strong lexical hindi signal in the residual stream rather than a persistent language‑mode state..
double-switch sentence : "i was going home jab baarish shuru hui and i got wet."
in the double‑switch sentence, the probe again jumps to high P(HIN) at the hindi boundary, but then falls back toward zero once the english continuation resumes.
this rise‑and‑fall pattern mirrors the lexical content: the classifier responds strongly to hindi tokens, but the signal decays when the sequence returns to english.
the behavior is consistent across base and hinglish models, suggesting that the probe is reading lexical hindi features rather than tracking a persistent language‑mode state across the second english segment.
stay tuned to know about this in detail!
benchmarks
for serving, mulberry builds on inference optimizations originally developed for llms. we adapt engines such as tensorrt-llm to our decoder architecture, allowing us to reuse mature serving infrastructure while supporting mulberry’s specific model design
on a single h100:
~80 concurrent real-time requests
<200ms time-to-first-audio
<0.9 real-time factor at 80-way concurrency
~162ms TTFB at ~5 concurrent requests
here, TTFB is the time from sending the request to receiving the first byte of the response, while TTFA is the time from sending the request to the first chunk of synthesized audio, after skipping past any container or header metadata.
mechanism
input: a short standardized text prompt of around 15-25 words, used consistently across all providers tested.
output: output format and sample rate kept fixed for all test runs.
geographic region: measured from a US-based client location, where we recorded a TTFA of 179ms.
mos scores
for quality, we use xls-r sqa mos as our primary metric. mulberry scores 4.23 ± 0.14, which puts it close to elevenlabs v3 (4.26) and gemini 3.1 flash tts (4.3). we're not claiming to beat the field, but we're competitive, and the voice control capabilities are meaningfully different.
instructTTS eval
since our model follows description style instruction following for speaker and other prosody features, we also evaluated our model on InstructTTS Eval, which is a benchmark designed to evaluate how well TTS systems follow complex natural-language instructions for controlling paralinguistic features (like pitch, emotion and prosody).
the benchmark consists of 6,000 test cases divided into three hierarichal tasks that progress from concrete control to abstract reasoning.
Acoustic-Parameter Specification (APS): Models are given explicit instructions for 12 fine-grained features (e.g., pitch, speed, volume, emotion).
Descriptive-Style Directive (DSD): Models receive more natural, free-form qualitative descriptions of a voice style.
Role-Play (RP): Models must infer appropriate vocal styles from abstract scenarios or character descriptions (e.g., "a teacher scolding a student").
for evaluating the audio generated for a given description, we used gemini 2.5 pro as judge (as used by authors) to give binary results (i.e. either pass or fail). the final score reported for each TTS system is the accuracy percentage, calculated as the macro-average of “True” judgements across all 1,000 test cases in a given subset.
on the instructTTS eval benchmark, mulberry hits 74.13% overall consistency. with scores of 75.30% on APS, 82.70% on DSD, and 64.40% on RP.
insights from pre-training
warm-start vs cold-start pre-training
when comparing the cold-start approach (scratch pre-training on text-audio pairs) against the warm-start approach (starting directly from a text base), the cold-start variant surprisingly comes out on top. as shown in the loss curves for both mulberry-small and mulberry-large, the cold-start runs yield a significantly smoother, more stable improvement over time. conversely, the warm-start configurations introduce frequent training instability, with small-warm-start even experiencing a massive loss spike midway through.
this distinct performance gap suggests that pre-trained text weights might actually conflict with or interfere with the model's ability to cleanly map acoustic inputs to text representations, a phenomenon noted and analyzed in the literature.
most of the plots and ideas (especially the equations) were taken from this paper and if you've made it till here, i definitely recommend you to give it a read.
data prep and formatting
for data preparation, we used a blend of synthetic and proprietary real-world audio, applying standard pre-processing steps like speaker diarization, background noise removal, and vad trimming. to prevent redundancy, we handled text de-duplication and canonicalization, then scaled our variations by pairing identical text with diverse audio descriptions and rvc-converted voices. rather than replacing features, we expanded the model's capabilities by introducing each new speaker category through dedicated description buckets. after initial pre-training on an internet-scale english speech corpus to lock in broad acoustics and coarticulation, we moved to sft using a curated mix of synthetic and studio voices that covered a wide array of regional accents, characters, and role variations.
our data formatting relies on a straightforward yet highly effective token recipe: interleaving text and audio pairs. as illustrated in the image above, this can be structured either as utterance-level interleaving or a more granular semantic and acoustic interleaving. by adopting this interleaved style for our tokens, the model easily learns the associative layout between audio-to-text or text-to-audio sequences without needing over-engineered training formats.
and what's next
if you're building with mulberry, the most important thing to keep in mind is that voice descriptions work best when they're grounded in the trait categories the model was trained on. the prompting guide walks through the supported attributes in detail, keeping your descriptions structured and consistent will get you the most predictable results.
that said, the generalization behavior means you have real flexibility in how you phrase things, even if the underlying traits are fixed. we're continuing to expand the set of supported accents, speaking styles, and code-switching behaviors, so if there are voice descriptions you want to see supported, that's the right place to start the conversation.
so take mulberry for a spin on the rumik playground now!