
encoder free models and the bitter lesson
encoder free models and the bitter lesson
published
published
june 15, 2026
june 15, 2026
we keep seeing sutton's bitter lesson play out again and again across modality interfaces. the same thing keeps happening we hand design some structure to get data into a model, an encoder or a codec or some special front end, and then once models get big enough we strip most of it away and feed the model something closer to the original signal.
gemma 4 12b did exactly this recently and so did thinking machines' interaction model. i want to walk through why i think this keeps happening.
the high level version is this. the structure never really disappears it just seems to move elsewhere. it moves out of the architecture you design by hand and into the model that learns from scale. so the input gets simpler while the model itself gets bigger and more general. that is the basic pattern.
why it keeps happening?
when you don't have much data or compute, hand-designed structure is genuinely useful. a good prior makes up for the data you don't have. cnn locality, mel's log-frequency warping, a codec's learned compression, these all tell the model "this is how the signal is shaped, you don't have to figure it out yourself." that's a real head start when data is scarce.
but when compute gets large, that same prior turns into a ceiling. now the model can learn the structure from data better than you designed it and your hand-coded front-end is just a constraint it has to work around. so the thing that helped you early starts hurting you later. that's the bitter lesson and it shows up in modality after modality.
images are the clearest case. we started with plain dense nets, then noticed images have structure a dense net throws away, so we built cnns to bake in locality. then vit came along and looked like it threw all of that out by just slicing the image into patches. but a 16×16 patch embedding is literally a convolution with stride 16. vit didn't drop convolution, it kept one thin conv stem and deleted the deep conv hierarchy, and let attention do the heavy lifting instead. hmlp is the same kind of thin, patch-local stem, just a few lightweight layers per patch instead of a deep encoder. the pattern isn't "simpler" it's a dumb input surface with a large, general interior.
audio went the same way: mel spectrograms, then cnns on top, then neural codecs to get discrete tokens and now people are circling back to much simpler feature/token interfaces like dmel.
what's happening now
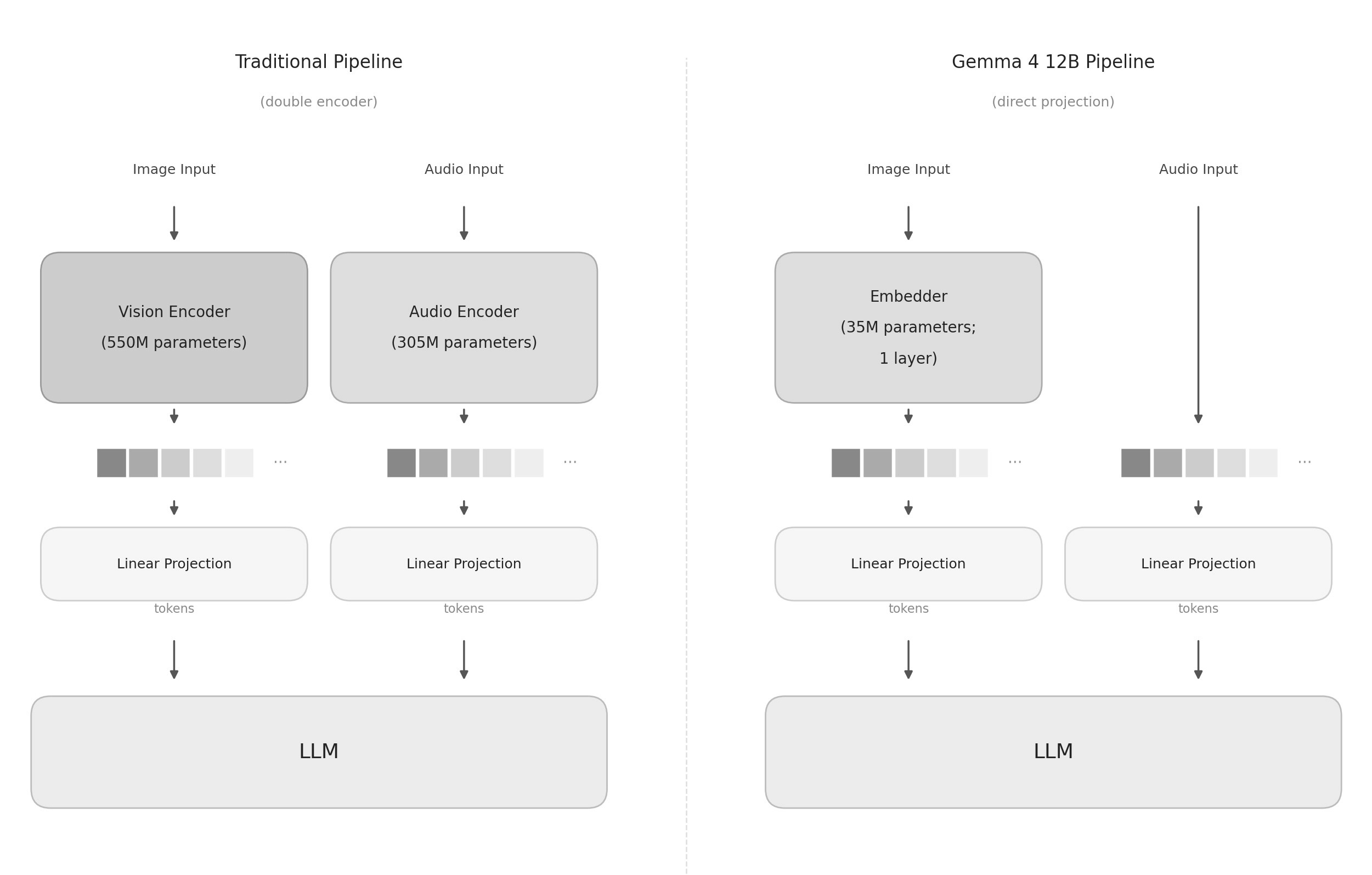
gemma 4 12b is the most concrete recent example. normally you'd run each input through its own dedicated encoder first, a vision encoder for images and an audio encoder for speech, each a sizeable network, before anything reaches the language model. gemma drops almost all of that. audio is projected straight in with no encoder at all, and images go through a tiny single-layer embedder instead of a full vision encoder.
many researchers assume that if they use muP (a method by Yang et al, 2022, for transferring hyperparameters across model sizes), they are safe from LR-tuning headaches.
thinking machines' interaction model is the same idea taken even further, because it's designed around this from scratch instead of trimmed down later. they call it encoder-free early fusion: audio in as dmel with a light embedding, images as patches, everything trained together from scratch, no separate speech model and no separate text-to-speech. they cite the bitter lesson directly, and they make the point sharper, the little hand-built component that detects when you have stopped talking is dumber than the model itself, so scaling the model just outpaces it.
thinking machines' interaction model is the same idea taken even further, because it's designed around this from scratch instead of trimmed down later. they call it encoder-free early fusion: audio in as dmel with a light embedding, images as patches, everything trained together from scratch, no separate speech model and no separate text-to-speech. they cite the bitter lesson directly, and they make the point sharper, the little hand-built component that detects when you have stopped talking is dumber than the model itself, so scaling the model just outpaces it.

but generation is a different problem
here's the part i find most interesting and it's where the pattern needs a caveat. there's a split hiding under the word "audio" and it's the reason the codec era wasn't actually a wrong turn.
codecs were driven by generation. if you want a model to generate audio autoregressively, you need discrete tokens, and codecs gave you tokens plus compression for free. the swing back to mel happened mostly because for understanding you never needed to reconstruct the audio in the first place. you just need features, and plain mel or a direct projection is simpler and works fine. reading a signal and producing one are not the same problem.
you can actually see this split inside the interaction model. the encoder is gone on the input side, but it still uses a dedicated flow head to generate the audio. reading is cheap: lightly transform or project the signal, then let the shared model do the work. producing is expensive: you have to synthesize a waveform that actually sounds right. so the input got simple while the output kept its own specialized decoders.
wrapping up
so the pattern is pretty consistent. as compute grows, hand-designed structure gets stripped out of the input and the model learns it instead. the input surface keeps getting dumber and the model keeps getting bigger and more general. we have now watched it happen for images and for the input side of audio.
the open question is whether the output side goes the same way. the input encoder can clearly be deleted. can the decoder be deleted too, could you eventually just predict the raw representation directly and drop the generation head? or is synthesis the one place where designed structure genuinely earns its keep and stays?
i don't have a clean answer. my intuition is that the input side always simplifies first and generation is the last thing holding on to designed structure. but the bitter lesson has a pretty good track record and i have learned not to bet against it too confidently.
this article was just to plant the idea. i will probably do a deeper post later on the actual representations: dmel, patch embeddings and flow heads.
but generation is a different problem
here's the part i find most interesting and it's where the pattern needs a caveat. there's a split hiding under the word "audio" and it's the reason the codec era wasn't actually a wrong turn.
codecs were driven by generation. if you want a model to generate audio autoregressively, you need discrete tokens, and codecs gave you tokens plus compression for free. the swing back to mel happened mostly because for understanding you never needed to reconstruct the audio in the first place. you just need features, and plain mel or a direct projection is simpler and works fine. reading a signal and producing one are not the same problem.
you can actually see this split inside the interaction model. the encoder is gone on the input side, but it still uses a dedicated flow head to generate the audio. reading is cheap: lightly transform or project the signal, then let the shared model do the work. producing is expensive: you have to synthesize a waveform that actually sounds right. so the input got simple while the output kept its own specialized decoders.
wrapping up
so the pattern is pretty consistent. as compute grows, hand-designed structure gets stripped out of the input and the model learns it instead. the input surface keeps getting dumber and the model keeps getting bigger and more general. we have now watched it happen for images and for the input side of audio.
the open question is whether the output side goes the same way. the input encoder can clearly be deleted. can the decoder be deleted too, could you eventually just predict the raw representation directly and drop the generation head? or is synthesis the one place where designed structure genuinely earns its keep and stays?
i don't have a clean answer. my intuition is that the input side always simplifies first and generation is the last thing holding on to designed structure. but the bitter lesson has a pretty good track record and i have learned not to bet against it too confidently.
this article was just to plant the idea. i will probably do a deeper post later on the actual representations: dmel, patch embeddings and flow heads.